Last year we upgraded from flux v1 to v2, flux v2 being a full rewrite, splitting the single binary into a number of dedicated controllers to improve performance. We installed flux v2 to each of our clusters, and let it run for a while before revisiting it to see what needed tuning, and what improvements could be made.
Controller behaviour and intervals
As we dug down into the documentation, we realised that our mental model of how the controllers worked wasn’t the whole picture. We’d been thinking about the four main controllers (image-reflector, image-automation, source and kustomize) as four totally separate entities, and accordingly set their “doing-stuff” intervals very low (typically ~1 min) thinking that that would mean changes were deployed quickly.
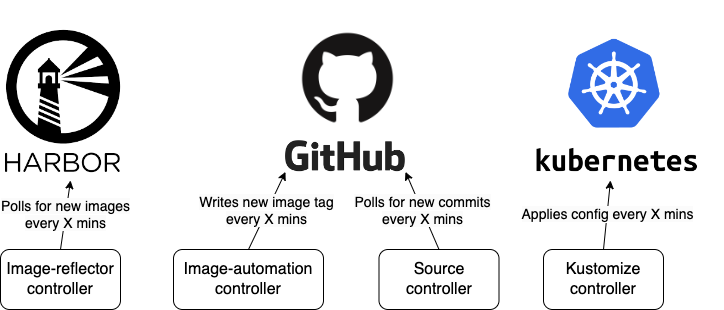
Incorrect model - no communication between controllers
As it turns out, there is a lot of interaction between the controllers, and the discovery of a new image or a new git commit initates a workflow that ends up in a kustomize controller reconciliation:
- The image-reflector controller polls the registry for new images every minute, but upon discovery of a new image it notifies the image-automation controller to write the new image tag to git.
- The source controller polls github for new commits, but when a new commit is discovered the it notifies the kustomize controller to start a new reconciliation.
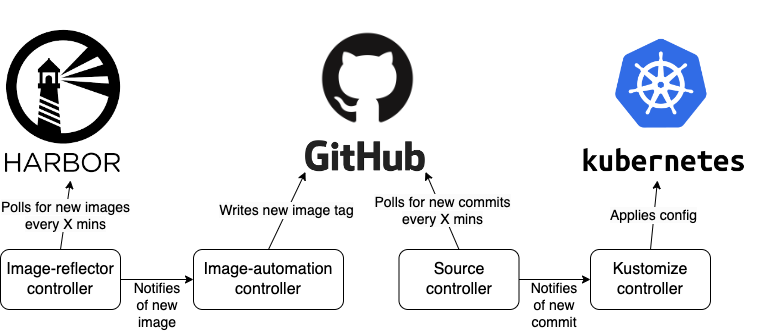
Correct model - communication between controllers
To improve performance further, we added a webhook so that a new commit to github would be pushed to the source controller.
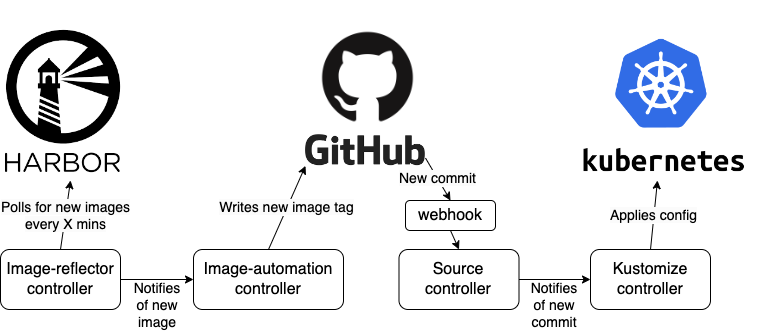
Improved model - webhook initiates reconciliation
Now we only need the image-reflector controller to poll the registry every minute; the other three controllers are event-driven, not interval driven.
This meant we could increase the interval timings to around an hour, and this would be primarily as a backstop (in case something broke) and to revert any manual changes made to the cluster.
Setting high intervals meant that the controllers were only invoked when there was action for them to take, and as a result ran much faster when a new image or commit arrived, instead of spinning constantly.
Limit yaml parsing
The other major improvement we made was to limit how much yaml needed to be parsed for each cluster. We have essentially a kubernetes monorepo, with config for all clusters laid out like
monorepo
- library
- cluster1
- cluster2
- cluster3
There’s no point parsing the yaml for cluster 2 when we’re reconciling cluster 1, so we limit this in the source resource like:
---
apiVersion: source.toolkit.fluxcd.io/v1beta2
kind: GitRepository
metadata:
name: kubeconf
namespace: flux-system
spec:
ignore: |
/*
!/cluster1
!/library
That is, ignore all yaml except what is directly applicable to this cluster.
The net result of these changes was that we went from an average of 10-20 minutes from a new image arriving in the registry to being deployed, down to 1-2 minutes.
Note: we used https://fluxcd.io/flux/guides/monitoring/#flux-dashboards for excellent insights into how flux was performing in the clusters.